
E6: SigNoz the open-source DataDog alternative

In this post I want to give some love to an open-source project that I have discovered just a few months ago: SigNoz.
There are a few commercial solutions that allow you to have metrics, logs and traces all in one place, such as DataDog or NewRelic. When you want to selfhost open-source solutions instead you were stuck with using multiple solutions and swichting between them. You might have been using Prometheus for metrics, Jaegar for Traces and Elasticsearch for logs - as an example.
All of these tools are outstanding in their own right and are great at what they do but there are some nice benefits to having all three (logs, metrics, traces) in one place.
Coincidentally, while I was in the process of writing this article there was also a huge DataDog outage which might make some people evaluate other options - including open-source ones.
So, let’s talk about
Observability & Monitoring
SigNoz & OpenTelemetry
The Community
And don’t forget to leave a star for them on Github, they deserve it.
Disclaimer: Observability and Monitoring are huge topics that won’t ever fit into a single blog post, if you really want to get into it I highly recommend the SRE book.
Observability & Monitoring
Observability is a property of a system, like functionality or testability. A system is considered “observable” if the current state can be estimated by only using information from outputs. These outputs are logs, metrics and traces, also known as the three pillars of observability. An application with great observability makes it easy for teams to analyze what is happening and enables them to quickly resolve the underlying issue.
Monitoring on the other hand is the active act of observing the system. In essence, monitoring technologies, such as application performance monitoring (APM), can tell you if a system is up or down or if there is a problem.
These two things usually go hand-in-hand as having better observability gives you more data to monitor and having great observability without any monitoring also means that you won’t ever know when something is wrong before the users complain.
If you search for these two terms online you will also find different definitions, for example some consider monitoring a subset of observability. As with many terms invented by our industry it’s hard to find a clear answer. In the end it will only matter that you know when something is wrong with your system and that you are able to resolve the issue.
When setting up monitoring for any system we generally want it to help us answer the questions: what’s broken, and why?
Note that these two questions often have totally different answers, what’s broken might be an application serving error 500s to users while the why might the server our application is running on is out of space or that a database might be refusing to connect.
What information do we need to answer these two questions? While you can monitor virtually anything about a system and sometimes it has to be decided on a case by case basis what is relevant information for a given system, the industry has generally come to agree on four factors that we should always have a close eye on - the four golden signals:
Latency
Traffic
Errors
Saturation
If you measure all four golden signals and send out an alert when one of them is problematic, your service will have at least somewhat decent monitoring.
How it works with SigNoz & OpenTelemetry
SigNoz relies on OpenTelemetry to gain insights into the performance of your applications. Once you have instrumented your application with OpenTelemetry, you send this data to the SigNoz Otel Collector, which will save it in a ClickHouse database.
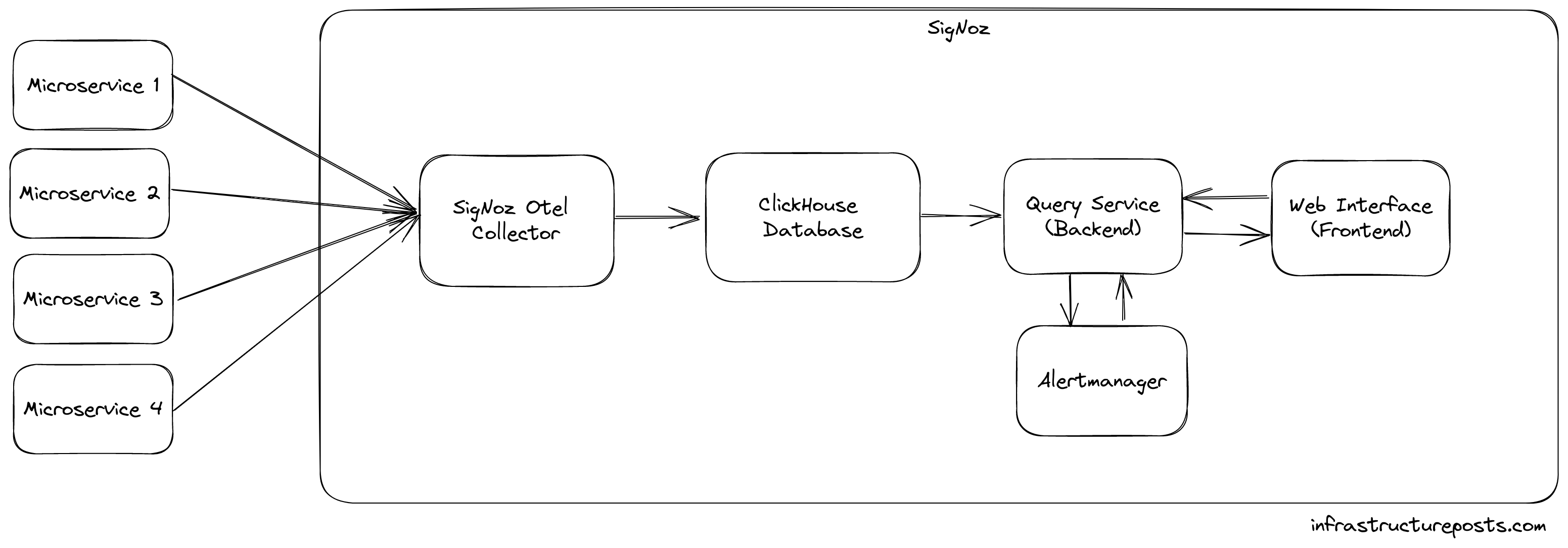
This is easy enough if you develop your application with OpenTelemetry right from the beginning and use it for all signals. When it comes to logging tho, most users will probably already be using a different library.
In those cases, it’s still easy to get your logs into SigNoz you can write your logs to a file and use the OpenTelemetry Filelog Receiver.

If advanced parsing and collecting capabilities are needed which are not present in OpenTelemetry or something like FluentBit or LogStash is already present then the agents can push the logs to the OpenTelemetry collector using protocols like FluentForward, TCP or UDP.

With the data in ClickHouse you can use the SigNoz web interface to gain insights into your applications state and performance.
I also love how sane their default configuration is. When we decided to deploy SigNoz into one of our test environments at work we simply added their helm chart to our Terraform repository and without setting any configuration options it just worked - see the code we used below.
resource "helm_release" "signoz" {
name = "signoz"
repository = "https://charts.signoz.io"
chart = "signoz"
create_namespace = true
namespace = var.namespace
}I was also amazed that I installed SigNoz in our k8s cluster and it was able to start ingesting k8s pod logs and metrics right away without requiring any further configuration.
The maintainers of SigNoz also provide guidance in how to setup OpenTelemetry and SigNoz for all kinds of different applications
And more - If you prefer videos over writing then they also have a series of on youtube on how to setup different their monitoring system for different applications, you can find it here.
The Community
What really made me fall in love with this project is how they treat their community. When discovering a new open-source software that interests me I generally start on the “issues” tab - this gives me a good idea of what’s going on in the project, how active the developers are and how they’re dealing with bugs and feature requests. SigNoz has to be one of the most active projects I’ve discovered so far - turning on notifications means that I can’t open Github anymore without seeing new discussions or pull requests.
You can also see the number of commits to the repository over time - these guys are killing it.

I’ve also Made a few small contributions myself (here, here and here) and felt very welcomed by the developers - looking forward to contribute more in the future.
If you’ve always wanted to contribute to open-source there are a lot of open issues with the “good first issue” label that you could pick up - if anything is unclear just ask and I’m sure they’ll be more than happy to help.
In addition to their activity on Github they are also happy to help anyone troublehsoot problems and discuss ideas on their slack channel.
Conclusion
So, why should you give SigNoz a chance?
Open-source
Awesome default settings
Very easy to setup and get started
Tries to do lot’s of common things - such as calculating p99 - automatically for you
Active community and developers who are willing to help you troubleshoot and fix things
All that being said, don’t exepect it to be as mature as DataDog just yet. They are still at an early stage with very active development so expect things to change / break when updating.
I am looking forward to see them develop this further and believe that they can give many of the commercial tools a run for their money.
Closing Words
I hope got value out of this and consider leaving your email address so that you don’t miss out on any of my future posts.
This newsletter is free but if you want to encourage me to keep doing this you can buy me a coffee.