
E5: Building Better CI/CD Pipelines

I’m personally in some kind of hate/love relationship with pipelines. I love them for all the work they do for me and could never imagine going back to a world without them.
I also hate it whenever I have to wait for a pipeline to finish. Eagerly wanting to know if my change is good and the pipeline passes or if there are problems I need to fix first. Depending on your pipeline this can take anywhere from 1 to 60 minutes. 1 Minute is a pipeline that just runs your unit tests and reports back if they pass or fail. A pipeline that is closer to 60 minutes is doing a whole lot more (at least I would hope so), static code analysis, unit tests, integration tests, linting, deployments to test environments, end to end tests - you can add a lot to your pipeline if you so choose.
However long your pipeline currently takes, you would probably prefer it to be faster and conveniently today I want to talk about a few things that may help you get there.
I have mostly been using Gitlab pipelines in my own career and I will be using Gitlab for all examples in this Post. That being said, most principles you find here can also be implemented in other CI/CD platforms like CircleCI or Github Actions.
Before we begin I want to at least establish some common vocabulary.
Runner → Maschine that executes the pipeline
CICD Platform → Where we define pipeline instructions, e. g. Gitlab
Job → A group of instructions that is executed by the runner
Stage →A group of one or more jobs, common stages are: build, test, deploy
The things I will be talking about here are:
When to run pipelines
Caching
Docker in Docker
All I say here stems from personal experience and your mileage may warry.
When to run pipelines
Using one repository for multiple applications seems to have become a popular approach in recent years, at least I have stumbled upon it on multiple occasions. I first hard about Google doing it and later discovered that there is even a word for it, Monorepo.
I have also seen some strange patterns emerge when following the monorepo approach, such as running all tests for all services whenever a change has been made to any service.
Always testing all applications in a repo with potentially 10s, 100s or even 1000s of them can be unfathomably time consuming. If you are using cloud provider to run your Pipelines, you might also have to pay more for the heavier load.
Just because all your applications and services are now living in one repository doesn’t mean that you should treat them like one single entity. In the world of microservices such an approach would be called a distributed monolith.
Many CI/CD platforms offer a way to check for changes to certain files or directories before running a pipeline. In Gitlab you can do it as follows:
only:
changes:
- dir-a/*
- dir-b/**/*
- file-cThis defines a pipeline that is only executed when
a) a file in dir-a has been changed
b) a file in dir-b or any subdirectory of dir-b has been changed
c) file-c has been changed.
In a monorepo this can be used to run the tests for a service only when files for this service change.
Builds and deployments should generally be handled similarly. They are all different services that just happen to have their code in the same repository, treat them as different entities.
What follows now is some rambling about Gitlab specific things that have annoyed me in the past, if you are not using Gitlab you can safely skip ahead to the next chapter about Caching.
Be aware that `changes` in Gitlab is always considered true when the pipeline is triggered via the web UI instead of by pushing code.
Another case I come across frequently is to manually trigger only certain parts of the pipeline and all CI/CD platforms should allow for this in one way or another. In Gitlab you can define custom variables before triggering a Pipeline manually and then check these variables for running certain jobs.
For example, if I have two separate test jobs defined, TestA and TestB then I can define that TestA may only run if the variable TEST_A is set to yes
only:
variables:
- $TEST_A == "yes"When you define many rules around when to run your pipelines, things can get a bit confusing, for example consider the following `only` definition. This Pipeline will run when either TEST_A or TEST_C is yes.
only:
variables:
- $TEST_A == "yes"
- $TEST_C == "yes"But what about the following?
only:
variables:
- $TEST_A == "yes"
- $TEST_C == "yes"
changes:
- dir-a/*
- dir-b/**/*
- file-cWell this will also run when the Pipeline is triggered manually and either TEST_A or TEST_C is set to yes. It will never run on any code push tho, because both the variables and the changes section have to evaluate to true. When you trigger the Pipeline manually, changes are always true, so in that case it works, but if you push code changes you never have custom variables defined thus your pipeline will never run.
More recently, Gitlab has introduced a new alternative to only in the form of rules. With rules I was able to get the behavior I actually desired, the Pipeline can be run manually by setting either TEST_A or TEST_B and the Pipeline will also automatically run all tests on a push that contains changes to the code.
rules:
- if: '$TEST_A == "yes" || $TEST_ALL == "yes"'
- if: '$TEST_B == "yes"
when: never
- changes:
paths:
- dir-a/**/*
- dir-b/**/*
Caching
Let’s say we have an application that is build using nodejs. Installing all dependencies for a big javascript application can take a while, so long in fact that the following has become one of the most wide spread memes among developers.

Which leads us to the conclusion, that we want to avoid downloading dependencies whenever possible.
How can we determine when the node_modules should be downloaded again? Pause here for a moment and think about it, it’s a good mental exercise.
The answer is to take a hash of the package-lock.json file. When this hash changes, the dependencies have changed in some way and need to be downloaded again. As long as this hash stays the same, we keep using the present node_modules and skip the download step.
Gitlab will do this hashing step for us if we us package-lock.json as the cache-key.
cache:
key:
files:
- package-lock.json
paths:
- node_modules/Using distributed caching
When you have one more than one runner for your pipeline, caching on the runner becomes less effective. You might have 6 jobs that run in parallel and that all need to be done before the next stage. If only one of these 6 jobs get picked up by a runner that doesn’t have his cache build up, this one becomes the bottleneck it almost doesn’t matter that we had a cache hit on the other 5.
In that case, it can make sense to store your cache in a remote storage such as S3 that all runners can access. Downloading your node_modules from S3 will of course be slower than having them cached locally but in my experience it is still a lot faster than running npm install.
Docker in Docker
Do you really want Docker-in-Docker? Or do you just want to be able to run Docker (specifically: build, run, sometimes push containers and images) from your CI system, while this CI system itself is in a container?
The above is a quote from this excellent article by one of the developers of docker, who has also worked on docker in docker. Since we are talking about pipelines here, we want the later. I strongly advise you to read their whole article but If you are short on time, you should mount the docker.sock of your runner into the container that executes the pipeline.
With this, when you use a docker command inside the docker runner, the command will be executed by the host docker engine. Meaning that instead of running docker containers inside docker containers you instead get the host to create a second container.
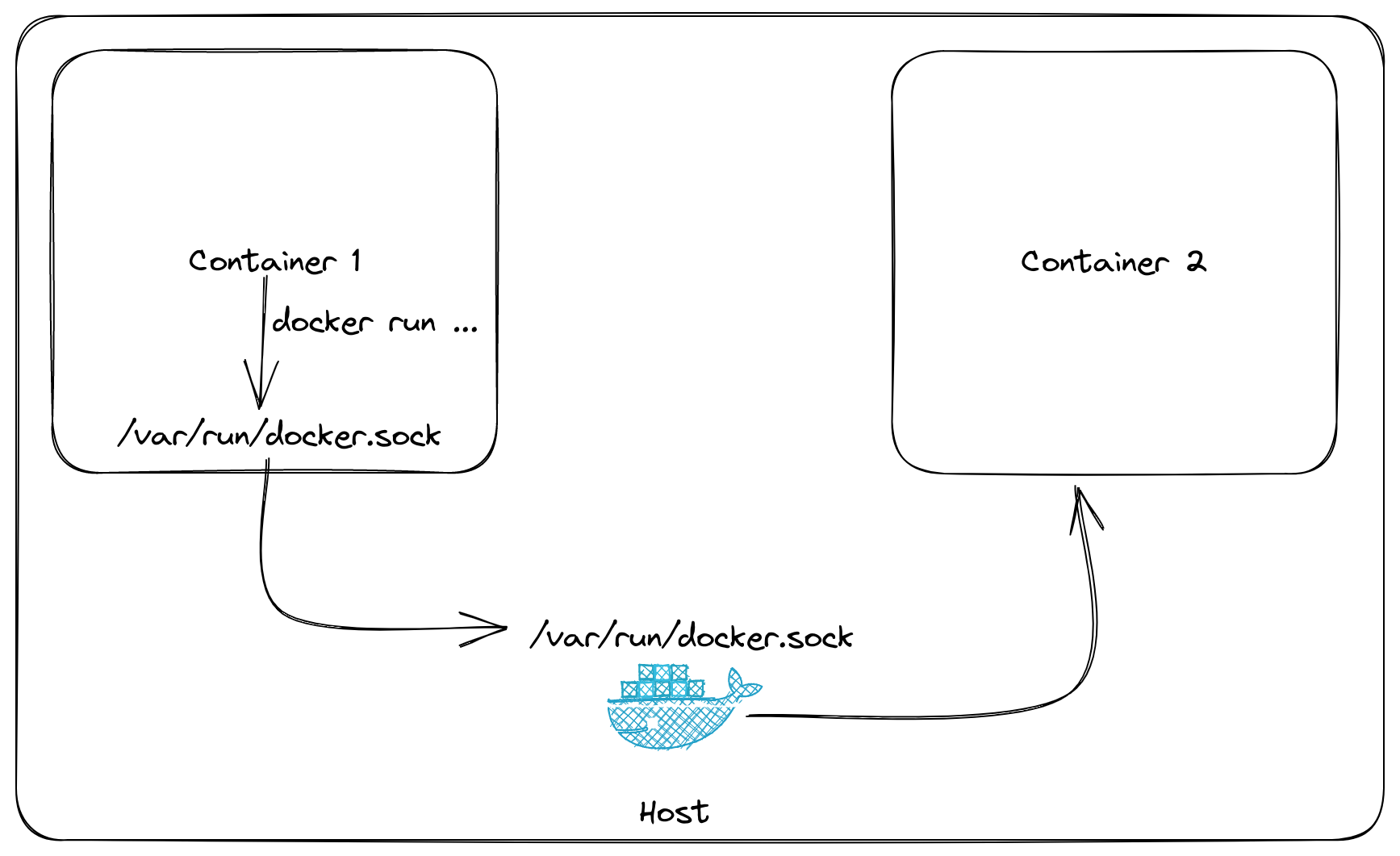
In Gitlab, you would do this by modifying the runner configuration as seen below.
[[runners]]
url = "https://gitlab.com/"
token = RUNNER_TOKEN
executor = "docker"
[runners.docker]
image = "docker:20.10.16"
privileged = false
volumes = ["/var/run/docker.sock:/var/run/docker.sock", "/cache"]Lessons learned
The most important take aways here are
Only test / build / deploy what has changed
Make use of caching mechanisms
Docker in Docker is often not necessary for CI purposes
Closing Words
I hope got value out of this and consider leaving your email address so that you don’t miss out on any of my future posts.
Also, we are hiring - so if you are you are in Germany (Hamburg) or willing to move here and you would like to join me, we are looking for DevOps folks as well as Go developers. Get in touch with me on LinkedIn if you wana know more.
This newsletter is free but if you want to encourage me to keep doing this you can buy me a coffee.